Abstract:
~~~~~~~~~
Widespread computer attacks and misuse are forcing organizations to formalize incident response plans and create dedicated incident response teams. These plans and teams have a key requirement to gather data from affected computers, which has historically been a manual and time consuming process. As a response to this growing problem,we developed the Remote Forensics System (RFS). The RFS application facilitates data acquisition, storage, and analysis in a forensically sound and efficient manner.
Chapter 1 : Introduction :
~~~~~~~~~~~~~~~~~~~~~~~~~~
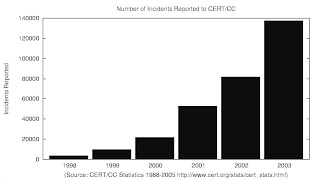
Organizations are increasingly adopting incident response capabilities in response to the rapid increase in the frequency of computer related incidents. Figure 1.1 shows the number of incidents reported to CERT (Computer Emergency
Response Team) from the year 1998 through 2003 [3]. It is likely that this trend will continue. Organizations must have the appropriate incident response capability to mitigate the impact of these increasingly frequent events. Incident
response is a complicated process that involves many players and has real consequences.
1.1 Incident Response:
~~~~~~~~~~~~~~~~~~~~~~~~
A high-level flow diagram of the incident response process is shown in Figure 1.2 [10]. The process begins with pre-incident preparation. Policies and procedures must be established and documented to support the incident response function. These documents, among other things, assign responsibilities for the incident response capability and establish the communication channels through which incidents are reported. The documents also describe the logging and monitoring configurations to assist in the capturing of incident evidence, as well as procedures for obtaining
baseline measurements for comparison with incident evidence.
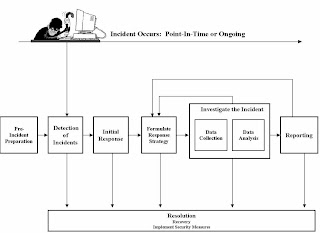
Once the organization is prepared for incident response, the incident response team can begin responding to incidents.There are various means through which incidents can be reported. Signature-based network intrusion detection systems
can be used to detect when network traffic matches a given signature. Host-based intrusion detection systems can be used to detect intrusions at the operating system level. Users may call the help desk to report that they have witnessed
an incident. All of these events are reported to the appropriate parties.
An initial response needs to be performed for every incident reported. The purpose of this response is to determine whether the reported incident warrants further investigation. Legitimate incidents are prioritized according to risk.
Assuming the incident warrants further investigation, the incident response team must next formulate a response strategy. The team decides whether to perform a live response and/or a forensic duplication of the hard drive. If a live
response will be performed, the response team will identify what data is to be collected and at what time the live response will be performed.
Once the response strategy is in place, the live response or forensic duplication of the victim machine1 is performed.After the data is collected, it is analyzed by a forensic examiner. The examiner attempts to reconstruct the incident from
the evidence in the system and network logs. Hopefully, this will reveal how the incident occurred and how it can be prevented in the future. When the forensic examiner has finished analyzing the data, the findings of the data analysis
are summarized in a report. During the data collection, data analysis, or reporting phases, the incident response team may determine that more data is required. If so, the process repeats itself with a new response strategy being formulated. This process continues until the examiner no longer requires additional data.
1.2 Why a Remote Forensics System?
Our product is called the Remote Forensics System, or RFS. It automates portions of the data collection and analysis steps shown in Figure 1.2. One challenge with data collection and analysis is the time required to complete these steps during complex incidents. Generally a forensics examiner must physically sit down at the victim machine and run the incident response tool kit on the machine to gather data. However, this is not a cost or time-effective solution and does not scale well. Our application improves the efficiency of data collection on a single or multiple victims, either locally or remotely.
When an incident occurs, it is very useful to know what the machine looked like before the incident happened so that the forensic examiner has something to compare the current state of the machine against. A forensic baseline is a snapshot of a machine at a specific instance in time. One of the main benefits of our application is that it automates the host baseline process. In settings where manual analysis is the only option, it is not feasible, for instance, to perform weekly baselines of all machines on a large network. This means a person would have to physically visit each machine once per week to gather these baselines. Automating the forensic analysis process makes scheduling frequent baselines feasible.
Our system assists in the reporting phase by presenting the results in a web-based utility that makes the results easy to analyze. It will allow the forensic examiner to compare the current analysis with any recorded baseline to see what has
changed on a machine since that baseline was recorded.
Chapter 2 : System Design :
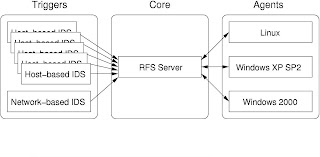
RFS is comprised of three primary components: Agents, Core, and Triggers, as shown in the high-level system architecture diagram in Figure 2.1. The Agents perform forensic acquisition of volatile and non-volatile system data on-demand and can be run on various operating systems. Shown in the middle of the diagram, the Core is a single machine that manages the Agent machines and requests and receives the forensic analyses that the Agents produce. The Triggers, shown on the left side of the diagram, are any event-generating mechanisms that can be customized to send
trigger data to the Core. Example Triggers include network intrusion detection systems (NIDS) and host-based intrusion detection systems (HIDS). Triggers help the Core determine when to request forensic analyses of Agents. The following sections go into further detail on the design of each module and the design of the system as a whole.
 2.1 RFS Goals :
2.1 RFS Goals :
RFS Design Goals:
~~~~~~~~~~~~~~~~~
1)Perform forensic analyses of local or remote machines
2)Initiate analyses:
a)On-demand
b)Periodically
c)Automatically in response to incidents
3)Collect and store information in a forensically sound manner
4)Minimize Trusted Computing Base (TCB)
5)Allow for extensibility
6)Facilitate and streamline analysis of results
The goals listed in Table 2.1 are the driving motivation behind the overall RFS design, and influence the design of each of the RFS components. We describe each goal here to provide a backdrop for the remainder of the system design.
2.1.1 Perform forensic analyses of local or remote machines
The ultimate goal of RFS is to perform automated analyses of remote machines, and this is the primary feature we seek to support. However, it is also important to be able to perform an analysis of a machine locally. There are two reasons for this. First, incident response professionals should be able to adopt RFS incrementally, using it initially simply as a replacement for the response kits they use to analyze machines locally, and later incorporating the full, remote analysis functionality RFS offers. Second, we want to retain the ability to respond to incidents in an ad hoc manner, for example if a machine is not connected to the network or has not yet had RFS installed.
2.1.2 Initiate analyses in different ways
This goal is closely related to the first goal. We need to support the following different methods of initiating analyses:
On-demand :
The user can initiate analyses when he chooses to. This supports the use of RFS for local ad hoc analysis, and for initiating analysis on a remote machine — for instance, if a new, non-scheduled baseline measurement is needed.
Periodically :
Analyses should be performed periodically to keep baselines up-to-date, so that the impact of incidents can be determined accurately. This is an area where RFS can save considerable time and effort, so support for this feature is a priority.
Automatically in response to incidents :
Finally, if an incident occurs, RFS needs to be able to respond to it by automatically initiating analyses of every potentially involved machine.
2.1.3 Collect and store information in a forensically sound manner
The results from a forensic analysis must be collected and stored in a forensically sound manner. The tools used in analyses are verified to establish trust, the communication between the analyzed machine and the RFS server is secure,
and the results are stored with date/time stamps and secure hashes of all of the results.
2.1.4 Minimize Trusted Computing Base (TCB)
The Trusted Computing Base (TCB) must be made as small as possible to minimize the chance that RFS itself becomes the target of attack, rendering collected evidence suspect.
2.1.5 Allow for extensibility
It should be simple to extend the capabilities of the system. The “best” response kit can change over time, so there needs to be a way to update the response kits easily. The means used to secure communications may also improve over
time, and some organizations may have specific security requirements, so communications security should be customizable. Finally, the product should be extensible to allow event-generating mechanisms to trigger analyses in
response to events that indicate potential incidents.
2.1.6 Facilitate and streamline analysis of results
The results of a single forensic analysis can be voluminous, and the collection of results from many machines over a significant period of time is astounding. Examining these results to find the cause and effects of an incident is
extremely challenging. RFS needs to provide a means to make accessing the correct results and comparing them to baseline results as easy as possible.
2.2 Agent
Once a response strategy has been formulated, data must be collected from the computers that were potentially involved in the incident. The RFS Agent facilitates the collection of this data. The Agent is fully configurable, and could collect any type of data; however, it should collect data most likely to reveal the nature of the incident. The default configuration gathers information such as system uptime, file system date/time stamps, and network connections. Details of the default configuration are covered in Section 2.2.3.
Throughout this paper, the collection of data from a single computer at a given time will be referred to as an analysis.Each analysis is comprised of a series of forensic tests. A forensic test involves running a trusted executable and
collecting its output. The collection of executables used to run an analysis is often termed a response kit. Standard incident response practice is to store a response kit on a trusted (and preferably read-only) medium, such as a CD.
When performing an analysis, the forensic tests are run directly from the trusted medium.
In essence, the RFS Agent is an automated, configurable response kit. It can be burned onto a CD and used to perform analyses just as a standard response kit would. Even in this basic use the RFS Agent offers many advantages over a standard response kit, because of its ease of configuration and use. However, the full power of RFS is realized when all components of the system are used together. In this scenario, RFS Agents run on all computers that could potentially be involved in an incident. If an incident occurs, the Agents on potentially affected computers are signaled to perform an analysis. Thus, the need for human intervention to collect data is eliminated.
2.2.1 Agent Goals
RFS Agent Design Goals:
~~~~~~~~~~~~~~~~~~~~~~~
1)Forensically sound data collection
2)Fully configurable, best practice forensic tests
3)Cross-platform
4)Usable as stand-alone tool or part of RFS architecture
Forensically sound data collection:
In designing the RFS Agent, the first and foremost goal is to build a tool that performs forensically sound data collection. The Agent does not necessarily run from a trusted, write-only medium. Thus, cryptographic mechanisms must be employed to provide a level of trust in analysis results similar to that of the results obtained by a human using a response kit run from a CD. Forensic soundness is discussed in detail in Section 2.2.2.
Fully configurable, best practice forensic tests:
A second goal is that the Agent be fully configurable. The end-user must be able to select which forensic tests are run during an analysis, in what order they are run, and which options they use. Related to this goal, however, is the need to
provide a usable and relevant tool out-of-the-box. Thus, it is equally important that the default response kit configuration include forensic tests that represent the best practices used by incident response professionals today. The
default configuration is covered in Section 2.2.3.
Cross-platform
Security incidents may occur on any operating system; thus, the next most important goal for the Agent is that it run on multiple platforms. There are two limiting factors: the language used to write the Agent itself and the forensic tests
comprising the response kit. The Agent is written in Java to make it as portable as possible. It will run on any platform that supports a Java 5.0 run-time environment. The use of Java creates some trade offs, which are discussed in Section 2.2.2. The forensic tests present a more difficult problem. These executables are generally platform-specific, thus a separate response kit must be assembled for each platform the Agent will run on. The default RFS configuration includes response kits for Windows XP SP2, Windows 2000, and Linux.
Usable as stand-alone tool or part of RFS architecture
Finally, the Agent must be able to operate as a stand-alone tool and as part of the RFS infrastructure. Two variables exist: how are analyses initiated and how are results stored? The Agent supports manual analysis initiated from the
command-line in either an interactive or batch mode. The Agent can also run as a daemon, initiating analysis in response to a signal from the RFS Core (the Core is discussed in Section 2.3). For result storage, results can either be
sent over the network or stored in a local file (saving a file on the hard drive of the computer being examined is not a good practice, but saving on a locally mounted USB key is a good option when network connectivity is absent or intermittent).
2.2.2 Forensically Sound Incident Response
Investigation of security incidents may reveal evidence of activity that requires disciplinary or legal action. As such, it is vital that the investigation itself be performed in a controlled and trusted manner, and that the data be trusted to be
untainted during collection, transmission, and storage.
Trusted test executables
The results of the forensic tests performed during an analysis are only as trustworthy as the executables performing those tests. If the test executables are replaced or corrupted, the results could be altered to hide or misconstrue
evidence.
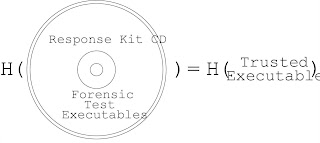
In a traditional incident response, the executables comprising the response kit are generally copied to a read-only medium from a source known to be trusted. Secure one-way hashes of these executables can be used to show that the version of the executable on the read-only medium matches the trusted version, as shown in Figure 2.2.
Because the RFS Agent does not necessarily run from a read-only medium, other means must be used to verify the executables comprising its response kit. Prior to running each forensic test, the Agent calculates a secure one-way hash of the executable, and verifies that the hash matches a trusted hash stored in the response kit’s configuration file (henceforth config).
Thus, trust that the forensic test executables have not been altered is reduced to trust that the config has not been altered illicitly. To verify the config, at first it seems reasonable to record a hash of the correct config in a secure location.
When an analysis is run, the config would be hashed, and this could be compared with the secure version to verify the config was not altered. However, this breaks another design goal — namely, that the Agent is easily configurable. If
every change to an Agent’s config required changing a trusted config in a secure location, ad hoc changes would be overly cumbersome.
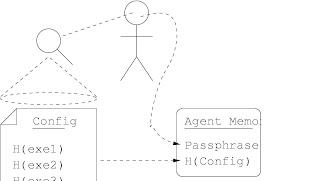
Our solution requires some human intervention. Instead of storing a hash of each Agent’s config, we store a pass phrase for each Agent in a secure location (the RFS Core). When the Agent is launched, the user is prompted to verify the config and enter the pass phrase, as illustrated in Figure 2.3. The pass phrase is not checked at this point, only stored in memory. In addition, a secure one-way hash of the config is also stored in memory. When the Agent begins an analysis,it verifies that the hash of the config matches the hash it has stored in memory — in other words, that the config hasn’t changed since it was verified by a human. When the Agent sends the analysis results, it also sends the pass phrase stored in memory, as shown in Figure 2.4. If this pass phrase matches the securely stored pass phrase, then the human who launched the Agent and confirmed its config was authorized to do so.
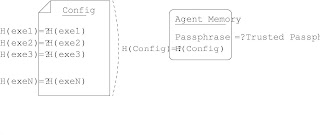
This solution relies on pass phrases remaining secure and humans performing a good job verifying the Agents’ configs. While there are a number of human problems with pass phrase security [9], the pass phrases will be compromised immediately in this solution if the communications channel is not secure. We cover securing communications in Section 2.5.
An additional consideration is the trustworthiness of the Java Runtime Environment (JRE) itself. RFS currently does not perform any verification of the JRE, as discussed in Section 3.4.
Minimal state alteration
A version of the Heisenberg uncertainty principle applies to collecting data from computers. By running an executable to determine a computer’s current state, that computer’s state is necessarily changed. At the least, the test executable
must be loaded into memory. This may in turn cause swapping, and writes to the computer’s hard drive. On top of this,the test itself may cause side effects. For example, collecting file system date/time stamps can alter the last accessed
time stamps of those files.
It is vital, therefore, that forensic tests be chosen carefully. Further, the order in which those tests are run is important in cases where data must be collected even though the test will cause significant state changes. Using the previous
example of file system date/time stamps, access times must be collected before modification and creation times. The default response kit configuration, as described in Section 2.2.3, was chosen carefully to record as much of a
computer’s state as possible without changing that state. When users customize their configuration this should be one of the factors they consider.
Aside from the response kit executables, the Agent itself causes some state changes. These are minimized to the greatest extent possible. However, because the Java run-time environment must be loaded to run the Agent, a sizable portion of memory may be swapped out when the Agent loads. Note, though, that if the Agent is running as a daemon (which is standard when running as part of the RFS infrastructure), the Java run-time will already be loaded when an analysis is requested. Other necessary state changes include opening ports for communication.
Secure transmission of results
Unless results are being save locally (for example, to a USB key), they must be transmitted to a collection station. In the full RFS architecture this is the RFS Core. If the Agent is being used by itself, the collection station may simply
have a port open that copies data it receives to a file (for example, netcat running in listen mode). Transmission of results involves two primary potential dangers: that the results could be altered before they are received by the collection station, or that sensitive data could be intercepted. A third danger is that a non-authorized program may send bogus data.
All of these threats — to data integrity, privacy, and authentication — can be solved by using Secure Sockets Layer (SSL) for communications. However, there are disadvantages to requiring a particular technology to address these threats. For example, some organizations may have particular requirements or custom solutions that preclude the use of SSL. Also, in the future a different technology may come into use that improves on SSL. Because of this, RFS uses Crypto Plugins to provide communications security. Crypto Plugins are discussed in Section 2.5.1.
We implemented two Crypto Plugins that are included with RFS — an SSL plugin and a plaintext plugin. The SSL plugin is intended for production use, because it provides the essential features of data integrity, privacy, and authentication. The plaintext plugin is included for testing and debugging, and should never be used in a production environment.
Fingerprinting results
Once the results of an analysis have been collected and stored, it is important to be able to show that those results have not been altered after-the-fact. A standard practice is to record a secure one-way hash of the results that is subsequently
written to a read-only or append-only medium, or even printed to hard-copy.
This task is not performed by the Agent, since the results have already been transmitted and are no longer under its control. In the case where the results are collected by the RFS Core, the Core records hashes that can later be burned to
CD or printed. In the case of an independent collection station, the human responder must capture a hash of the results.
2.2.3 Best Practice Forensic Tests
In this section we discuss the specific forensic tests included in the Agent’s default response kit configuration. These tests were chosen to answer a series of questions that are significant during an incident investigation. Further, as
mentioned above, the order of the tests is important in cases where a particular test may alter the state of the computer being examined. The tests are presented here in the order they are run during analysis.
Because the running time for some forensic tests may be quite lengthy, the Agent supports two different analysis types: standard and full. Each test in an analysis is marked whether it should only be run during full analyses or during both
standard and full analyses. Depending on the severity of the incident being investigated, either a standard or full analysis can be run.
Who is currently logged on?
If an incident has just occurred, there is a possibility that someone currently logged onto the system is responsible.Therefore, the first information we want to capture is who is currently logged on, to minimize the chance of log offs before this test is run. This test runs during both standard and full analyses.
Windows XP SP2 and Windows 2000
psloggedon.exe
Part of the PsTools suite of utilities available from Sysinternals [16].
Linux
w
Standard Linux utility.
How long has the computer been running?
A system’s uptime can be an important clue, especially in the case where it reveals that a computer was rebooted just
before or after the time of an incident. This test runs during both standard and full analyses.
Windows XP SP2 and Windows 2000
psinfo.exe -h -s -d
Another PsTools utility. In addition to system uptime, this utility reports a wealth of other information about the system being examined.
The command line options, -h, -s, and -d, instruct psinfo.exe to report on installed hotfixes, installed applications, and disk volume information, respectively.
Linux
uptime
Standard Linux utility.
When were files last accessed, modified, and created?
Changes to the file system provide excellent evidence for determining the cause of an incident. As mentioned previously, it is important to obtain access times first, because traversing the file system obtaining date/time stamps can change access times. These tests run during both standard and full analyses.
Windows XP SP2 and Windows 2000
cmd.exe /C dir /t:a /a /s /Q /o:d c:\
cmd.exe /C dir /t:w /a /s /Q /o:d c:\
cmd.exe /C dir /t:c /a /s /Q /o:d c:\
cmd.exe /C attrib C:\*.* /S /D
The standard Windows shell’s dir command is used to obtain file date/time stamps. The attrib command is used to obtain file attributes, since the dir command cannot do this like the ls command does in Linux.
The /t option indicates which type of time stamps to acquire: a for access, w for modification, c for create. /a indicates all files should be listed, including hidden files. /s requests a recursive file listing, so that all directories and
subdirectories are listed. /Q shows files’ owners. /o:d sorts by date. Finally, c:\ indicates the listing should begin from the c:\ drive. If a computer has a different drive letter, this test should be changed to reflect the proper drive letter, and
if multiple drives exist, the test configuration should be duplicated for all the drives that need to be examined.
Linux
ls -alRu /
ls -alRc /
ls -alR /
Standard Linux utility. The a option indicates all files should be listed. The l option uses a long listing format that includes file attributes. R causes a recursive listing. u lists access times, c lists modification times, and without u or c,create times are listed.
What network connections are open?
Many malicious programs open network connections. Checking which connections are open may indicate whether a computer has been infected with a back door, Trojan, or other malicious program.
Windows XP SP2
netstat.exe -ano
netstat.exe -anbv
fport.exe
netstat.exe is a standard Windows utility for reporting network information. fport.exe is a utility written by Foundstone [6] that identifies applications associated with open ports.
The netstat.exe a option displays all connections and listening ports. The n option indicates numerical addresses and ports should be used. o displays the owning process ID for each connection. b displays the executable involved in
creating each connection, and v displays the sequence of components involved in creating each connection.
The b option to netstat.exe essentially duplicates the functionality of fport.exe. However, netstat.exe runs very slowly with the b option, while fport.exe runs quickly. Thus, netstat.exe -ano and fport.exe are included in standard and full analyses, while netstat.exe -anbv is only included in full analyses.
Windows 2000
netstat.exe -an
fport.exe
The Windows 2000 version of netstat.exe does not include the o or b options. Thus, fport.exe is the only means to determine a mapping from open ports to processes on Windows 2000.
Linux
netstat -an
netstat -anop
Standard Linux utility. The a and n options are the same as for Windows. The o option includes information about networking timers, and the p option shows the process ID and name of the program to which each connection belongs.
What processes are currently running?
An unsophisticated malicious program may be trivially detected by checking the process list. Even if a program disguises itself as a legitimate process, suspicion may be raised if multiple versions of the same process exist.
Windows XP SP2 and Windows 2000
pslist.exe -t
pslist.exe -x
Part of the Sysinternals PsTools suite. The -t option displays the process list in tree format, so the hierarchical relationships between processes are apparent. This test is run during standard and full analyses. The -x option also includes thread information, although this test is only run during full analyses.
Linux
ps auxw
Standard Linux utility. The a option lists all processes, u displays a user-oriented output format, x includes processes that do not have a controlling tty, and w causes the output to use a wide format.
What dynamic link libraries (DLLs) are loaded?
On Windows computers, a list of loaded DLLs can be helpful in investigating an incident. This test runs on light and full analyses.
Windows 2000
listdlls.exe
A utility available from Sysinternals that lists loaded DLLs. This utility can cause system instability on Windows XP when the cygwin UNIX emulation environment is in use. Thus this test is disabled in the default Windows XP configuration. If cygwin is known not to be in use on the computer being examined, this test can be re-enabled.
What network configuration information is available?
Data about network configuration such as the IP routing table and IP interface configuration can assist in incident investigation.
Windows XP SP2
netstat.exe -rn
arp.exe -a
netstat.exe -es
ipconfig.exe /all
ipconfig.exe /displaydns
While netstat.exe was used previously to report on open connections, the r option outputs the IP routing table, and the e and s options report Ethernet and protocol-specific statistics, respectively. arp.exe -a displays the
Address Resolution Protocol cache. ipconfig.exe /all displays IP configuration information for all network interfaces, and ipconfig.exe /displaydns outputs the Domain Name Service cache.
All of these tests are run during full analyses only, except for netstat.exe -es, which is also run during standard analyses.
Windows 2000
netstat.exe -rn
ipconfig.exe /all
Not all of the test options available on Windows XP are available on Windows 2000, therefore we only run these two tests.
Linux
netstat -rn
ifconfig
Standard Linux utilities. They report on the same information as their Windows equivalents. ifconfig is the Linux equivalent to Windows ipconfig.
What services are installed?
On a Windows computer, it is helpful to know which services are installed. This test is only run during full analyses.
Windows XP SP2 and Windows 2000
psservice.exe
Part of the Sysinternals PsTools suite which displays all configured services, whether they are running or stopped.
What log information is available?
Log files may contain significant data concerning the events before, during, and after an incident. Because log data could be very large, this test is only run during full analyses.
Windows XP SP2 and Windows 2000
auditpol.exe
ntlast.exe
psloglist.exe -x system
psloglist.exe -x security
psloglist.exe -x application
auditpol.exe is a Windows utility that reports the current auditing policy. ntlast.exe is a Foundstone utility that extracts logon/logoff events from the system log.psloglist.exe is another component of the Sysinternals PsTools suite — it extracts the entire contents of Windows event logs. The -x option specifies which log to extract.
Linux
last
Standard Linux utility. Displays the record of users logged in and off in /var/log/wtmp.
What kernel modules are installed?
On Linux systems, certain attacks may attempt to alter the kernel to hide evidence. One way to do this is by loading a kernel module. While a sophisticated attack could hide the fact that the kernel module was loaded, a listing of loaded kernel modules will discover less sophisticated attacks of this sort. This test only runs during full analyses.
Linux
lsmod
Standard Linux utility for listing loaded kernel modules.
What information about mounted file systems is available?
In Linux, knowing what file systems are mounted and how much space each has available is good background information for an investigation. This test is only run during full analyses.
Linux
df
Standard Linux utility for reporting file system disk space usage.
What are the contents of the registry?
Many details about a Windows computer’s current state is captured in the registry. It can provide important clues about an incident. Because a full registry dump is lengthy and produces large output, this test is only run during full analyses.
Windows XP SP2 and Windows 2000
regdmp.exe -i 2 -o 120
Part of the Microsoft Resource Kit. The -i option specifies the indent level, and the -o option specifies the width of the output.
Have users been added or passwords changed?
Many attacks involve adding users or changing passwords. A simple way to determine whether this has happened is to check the system’s password hashes. This test is only run during full analyses.
Windows XP SP2 and Windows 2000
pwdump3.exe 127.0.0.1
Free utility written by Phil Staubs for extracting Windows password hashes [18]. This tool is often part of an attacker’s toolkit, because once password hashes are obtained, an offline dictionary attack can reveal the passwords. Nevertheless,
it is also useful in analyzing incidents since it will reveal whether any users have been added or their passwords changed.
Linux
cat /etc/passwd /etc/shadow
cat is a standard Linux utility for displaying the contents of a file. /etc/passwd contains a listing of users and historically also contained password hashes. However, on today’s Linux systems the password hashes are stored in /etc/shadow.
What files are open?
A final piece of evidence that may be useful is what files are currently open. This test is only run during full analyses.
Windows XP SP2 and Windows 2000
handle.exe
A utility by Sysinternals for listing references to system objects. The default usage is to list all file references.
Linux
lsof
Standard Linux utility for listing open files.
2.3 Core
The Core composes the largest portion of the RFS’s trusted computing base (TCB). It acts as a central management,storage, and presentation facility for forensic results. Through its interaction with Agent machines, the Core can request
an analysis of any machine registered to the RFS server2 as well as receive forensic analyses from machines that are not registered. The Core additionally listens for forensic analysis Triggers. Any configurable, event-generating
mechanism can be a Trigger. Triggers simply send trigger data to the Core in response to events. The Core then examines this data to determine which Agents should be analyzed in response to the Trigger.
2.3.1 Core Goals
RFS Core Design Goals:
1 Store data received from Agents
2 Manage enterprise data acquisition process
3 Facilitate data analysis
The Core’s design goals are listed in Table 2.4. The major function of the Core is to store data received from Agents.The Core acts as a central repository for response kit data so that results can be centrally secured, maintained, and
monitored. The second goal of the Core is to manage the enterprise data acquisition process. The Core achieves this via its interaction with Trigger devices on the network, its periodic triggering of baseline analyses, and its management of
the database of registered Agent machines. Finally, the Core facilitates data analysis through a web interface that allows the forensic examiner to easily access pertinent data.
2.3.2 Store data received from Agents
Collecting the results of all forensic analysis in a central location has two primary advantages. First, it makes examination and cross-correlation of results easier. Second, and perhaps more importantly, it is easier to assure that the
results files have not been tampered with after collection, since there is only one storage location to secure.
Receiving data
Interaction with Agents is the key function of the Core. Within the Core, an analysis submission listener continually listens for analysis submissions from Agent machines on a known port. This port is defined in a configuration file.
There are two scenarios in which the Core can receive analysis submissions. In the first scenario, the Core itself requests an analysis from the Agent. The Agent responds to the Core’s request by performing an analysis and sending
the results to the Core. In the second scenario, a human runs an Agent in stand-alone mode (see Section ) on any machine and sends the results to the Core. In either case, the analysis submission listener receives the data.
Results Storage
After results have been received they must be stored indefinitely. RFS provides two options for results storage: flat-files or CVS (Concurrent Versions System [4]). The storage scheme is specified in the Core’s configuration file.
In flat-file storage, the Core creates a new directory for every analysis. Within this directory, the Core creates a separate file to store the results of each forensic test run during the analysis. Thus, if each analysis contains n tests and there are p analyses, then n⋅p flat-files will be stored. This storage scheme is straight-forward but does not conserve storage space, because result files contain a significant amount of redundant information. For instance, there may be full
directory listings from n different analyses for any given Agent machine. If each directory listing requires O(m) storage space, then the total storage required in the flat-file scheme is O(nm). But from one analysis to another the directory
structure changes very little.
The CVS storage scheme addresses this inefficiency. CVS is generally used as a source code control tool, and one of its primary features is the ability to store different versions of the same file efficiently. It does this by only storing the
differences between versions of the file. Any version of the file can be recalled by starting from the base version and successively applying the saved differences.
Thus, if n nearly-identical file directory listings of size O(m) are stored using CVS, the storage space required will be O(m+n[epsilon]), where [epsilon] is the average size of the differences between directory listings. The majority of
analysis results do not significantly change over time in the common case (in other words, [epsilon] is very small), so CVS provides significant storage efficiency.
The cost of this space savings is slower retrieval of results, because each individual result file must be rebuilt by applying all the differences to the base version. However, this slower retrieval time is rarely noticeable. The exact
space savings of CVS storage depend on analysis frequency (daily analyses will generally have fewer differences than weekly analyses) and nature of use (a multi-user machine will generally have more differences than a single user machine).
2.3.3 Manage enterprise data acquisition process
Collecting analysis results at the enterprise level requires careful management of the entire process. The RFS Core has a number of features specifically for this purpose.
Periodic Triggers
The Core manages periodic triggers for every registered machine. The periodic trigger initiates scheduled analyses so that forensic baselines can be gathered at a specified frequency. Collecting baseline data frequently helps forensic
examiners in determining how a system has changed over time. The number of hours between scheduled baseline analyses as well as preferred scan time are configurable through the Core’s GUI.
Agent Identification
In order for the Core to manage analysis results and request analyses, the Core must have a persistent, unique identifier for every registered Agent machine. We identified a number of machine attributes that can contribute to uniquely
identifying machines on the network.
1. IP Address
2. MAC Address
3. Machine Name
4. Random String assigned at install-time
Any of the first three cannot be used as a unique identifier. IP addresses are not persistent and may change due to DHCP. Additionally, if many hosts are behind a Network Address Translation (NAT) device, all hosts behind the NAT will have the same “unique” identifier, which defeats the purpose. MAC addresses cannot be used alone because network cards can be replaced, and software overrides can be used to change the MAC address of a network interface card. The machine name is not persistent because naming schemes change, and the machine name is not guaranteed to
be unique.
Using the hard drive serial number would be a better unique identifier because the serial number is unique, persistent,and physically tied to the contents of the disk. However, hard drive serial numbers are difficult to learn in software,
because the method of accessing the serial numbers changes across vendors and across operating systems. WinSim,Inc. provides an open-source utility, DiskID32 [23] to learn hard drive serial numbers in Windows. However, they warn that the utility may cause the PC to lock up. This would create a forensic nightmare, and should be avoided at all costs.
A random string unique identifier is the best mechanism for uniquely identifying machines on a network, independent of whether the other identifiers change. This is the mechanism used by RFS. The random string is called the machine ID. It is maintained at the Core, not at the Agent. If machine IDs were stored by Agents, the ID itself could become corrupted by being erased or changed. In order to prevent corruption of the machine ID, the Core maintains each machine’s ID along with each machine’s last known IP address, MAC address, and machine name. This data allows the
Core to intelligently translate from 〈IP Address, MAC Address, Machine Name〉 to the machine ID. This scheme is fairly robust to hardware and OS failure. If an Agent’s network card goes bad and the MAC address of a machine changes, the Core will still be able to identify the machine by identifying its IP address and/or machine name. If the hard drive crashes, and the machine name is lost, the MAC address will still persist and the IP address may persist as well. Finally, if the IP address changes due to DHCP or other reasons, the MAC address and machine name can be used
to resolve the machine ID.
Using this machine ID scheme, a problem arises when an Agent’s IP address changes. The Core needs to be able to translate from machine ID to IP address to initiate communication, for example, to run a periodic baseline analysis. If
an Agent’s IP address changes, the Core will be unable to perform the scheduled baseline, because it will be contacting the old IP address. To allow the Core to learn of new IP addresses, MAC addresses, and Machine Names for a given unique identifier, each Agent periodically updates the Core with it’s latest contact information.
If a machine is unable to be identified by its IP address, MAC address, and machine name, the forensic results are placed in a quarantine directory for manual analysis by a human. Refer to Section 3.10 for attacks on this identification scheme.
Rate Limiter
The Core cannot simply request an analysis in response to every trigger received. It must protect itself from taking on too many tasks, and be smart enough not to request an analysis of a machine too soon after the previous analysis of that
machine has completed. For this reason, the Core contains a rate limiter that makes decisions on whether or not to request analyses of Agents based on historical data.
The rate limiter has various pieces of information from which to decide if an analysis should take place. For each machine, the rate limiter knows whether or not an analysis is currently being performed, whether or not the last
requested analysis was successful, as well as the priority threshold of the machine.
Triggers received by the Core have a priority level associated with the data. The priorities range from 0 to 5, 0 being least severe and 5 being most severe. Each machine has a priority threshold that defines for which priorities the
machine should be analyzed. For instance, a mail server may have a priority threshold of 1, which means all triggers with a priority greater than or equal to 1 should trigger an analysis of the mail server. A less critical system may have a
priority threshold of 4, so that only triggers with priorities 4 and 5 will trigger an analysis (note: analyses triggered manually through the Core’s GUI are always given the highest priority level of 5).
The rate limiter first checks whether the machine is currently being analyzed. If it is, it denies the analysis request regardless of the trigger priority. Next the rate limiter determines if the last analysis succeeded. If not, the rate limiter
grants the analysis request regardless of the priority level. The reason for this is that if the last analysis failed, the machine might be overdue for analysis. Next the rate limiter consults the machine’s priority threshold. If the priority for
this trigger is greater than or equal to the machine’s priority threshold, the rate limiter grants the analysis request. Otherwise, it denies the request.
The rate limiter does not use the date of last analysis and preferred scan frequency in its decision making because these items are already taken into consideration by the periodic triggering mechanism. After each successful and unsuccessful analysis of a machine, new analysis tasks are scheduled by the periodic scheduling mechanism using this information.
Job Assignment
Once the rate limiter approves a request for forensic analysis of an Agent, the next step is to initiate the analysis. The data needed to initiate the analysis is encapsulated in a task object. The Core launches a new thread for each task, but
because the Core’s resources are limited, only a certain number of threads may run at one time. Thus, tasks must be submitted to a task queue where they wait for the next available thread.
The task queue is implemented as a PriorityBlockingQueue, which is a member of the Java Collections Framework [20]. The task queue maintains a thread pool and a task backlog. The thread pool is a configurable number of threads that are available at any given time to request an analysis of an Agent machine. Once every thread in the
thread pool is occupied, the backlog begins accumulating tasks. The size of the backlog is configurable. Once the backlog is full, incoming tasks are dropped. If this is an undesirable side-effect, the backlog size can be configured as
unbounded (tasks will never be dropped).
Agent Updater
The Core allows the administrator to modify a central response kit configuration for all the Agent machines and push the new configuration out to all of the registered Agents. This is a valuable feature, because it prevents the administrator from having to unnecessarily visit each Agent machine to update the response kits.
Event Logging
Like other production servers, the RFS Core logs events that occur in a log file. Example events include RFS startup and shutdown, analysis begin, analysis end, trigger received, configuration changes, machine registrations, and general
failures.
2.3.4 Facilitate data analysis
Web Interface
The final goal of the Core is to facilitate data analysis by the forensic examiner. The Core has a built-in web interface that interacts with CVS to allow examination of completed forensic analyses. The port on which the web server operates is configurable.
The web interface allows the forensic examiner to browse the forensic results database. Analysis results are organized by machine. Once the examiner selects a machine, the dates and times of all stored forensic analyses for the given
machine are displayed. The examiner selects an analysis date/time, and is presented with the set of forensic tests that were run during the given analysis. The examiner can view or download the results of these tests, or compare the differences between two analysis sets to reveal how the test results have changed over time.
The Core also comes with extra HTML files that can be used to create a frame-based web interface that has the above-mentioned features plus context-sensitive help. To use this “full” web interface, a general-purpose web server such as Apache or Microsoft IIS is needed.
2.4 Trigger
After detection of an incident, but prior to actually collecting data, the “initial response” and “formulate response strategy” phases of the incident response process must take place (see Figure 1.2). Essentially these consist of determining which machines may have been involved, and deciding how much and what type of data needs to be acquired. In traditional incident response, a human must be involved in these phases. The RFS Trigger largely automates this process, providing the link from automated incident detection by an IDS to automated incident response.
The RFS Trigger provides a means for a third party (the triggering mechanism) to initiate analyses. Any third party software that has the ability to execute the Trigger can request an analysis, assuming the Trigger machine is authorized
to make the request. As shown in Figure 2.1, Triggers are typically located on separate machines from the Core and Agent. However, each component may also be co-located on the same machine, and multiple Triggers may exist on the
same machine if that machine has multiple triggering mechanisms installed.
2.4.1 Trigger Goals
RFS Trigger Design Goals
1 Initiate the data acquisition process in response to external events
2 Respond intelligently to events
Initiate the data acquisition process in response to external events
The Trigger is designed to remotely initiate the data acquisition process by responding to events. These events may come from any event-generating mechanism, such as intrusion detection systems or other third party software. Triggers
can also be initiated in response to a manual request.
Respond intelligently to events
The Trigger needs to gather sufficient event data so that it can intelligently respond. The Trigger must assign a priority level and an impact level for each analysis request that it sends to the Core. The criteria for determining priority and
impact levels must be configurable.
2.4.2 External Events
In our development and test environments, Snort, an open-source IDS [15], was used to send triggers3 to the Core. The only customization to Snort consisted of ensuring that Snort was logging to syslog.
SWATCH [1], a third-party log monitoring utility, was configured to watch for Snort alerts in syslog and parse the alert information to determine the data to send in the trigger. SWATCH can be configured to monitor any file for lines that match a given regular expression and to take a specified action when a line is matched. We configured SWATCH to watch the syslog files for Snort alerts and execute the Trigger executable when a new Snort alert was detected.
We configured SWATCH to provide the victim IP address, source IP address, priority level, as well as a copy of the alert contents to the Trigger executable, which in turn, sent a trigger packet containing this information to the Core. The
victim IP address is the IP address that the alert indicates was the victim of the attack. The source IP addresses is the IP address that the alert indicates was the source of the attack. The priority impact level values are used by the Core to
prioritize and filter triggers. Priority values are customizable by editing the classification.config file for Snort.
2.4.3 Communication with the RFS Server
The next step is to send the trigger information to the RFS Core. Like all RFS components, the Trigger uses the communications API, described in Section 2.5, to send data data to other RFS components.
During connection establishment, the Trigger must be authenticated. This is handled by the Communication API’s Crypto Plugin, described in Section 2.5.1. Authentication of Triggers is necessary, because otherwise an attacker could flood the RFS with analysis requests. Such a denial of service attack on the RFS Core could allow an attacker to hide or obscure their attack.
2.4.4 Impact Analysis
Once the RFS Core has received the trigger information, an impact analysis of the alert information is performed. The purpose of the impact analysis is to determine how much of the network might be affected by the alert. There are three
alert impact levels: low, medium, and large. The impact analysis is performed at the Core, as opposed to at the Trigger machine, because the Core has a much more complete picture of the network infrastructure.
Low Impact
A low impact trigger indicates that the alert does not impact machines other than the source and destination. Analyses will be requested of both the source and destination machines, assuming they are registered to the Core. By requesting
an analysis of the victim, information about the attack can be gathered such as any potential compromise and information to create better IDS signatures. By analyzing the source machine, it may be possible to determine if the machine has already been compromised as well as the vulnerability that led to the compromise.
Medium Impact
A medium impact trigger indicates that the alert could affect other portions of the network beyond just the machines directly involved in the alert. For example, if an SMTP server has been attacked, it may be wise to analyze the other
SMTP servers to determine if they have also been affected. Configuration of the medium impact machine groups consists of adding a list of IP addresses or a range of IP addresses to a configuration file. If one of the IP addresses in the list or range is affected by the alert, then the other machines in the list or range will also be analyzed.
Large Impact
A large impact trigger indicates that the entire network could be affected. Potentially every known machine on the network could be analyzed in response to a large impact trigger. Configuration of the large impact criteria consists of
adding keywords to a configuration file. If an alert contains the keyword, an analysis is requested of all machines registered to the Core.
After the impact analysis has been completed, the information and request are handed off to the Core, which may ultimately decide to request an analysis from involved Agent machines. The rate limiter (section) must still approve the analysis requests for them to actually be carried out.
2.5 Communication API
RFS requires considerable intercommunication between Agents, Core, and Triggers. Further, most of these communications require data integrity, privacy, and authentication. To simplify development, we designed a communication API used by all RFS components. This prevented re-inventing the same networking code in each
component. It also made possible our Crypto Plugin paradigm (discussed later in this section), which removes dependency on any one technology to provide data integrity, privacy, and authentication.
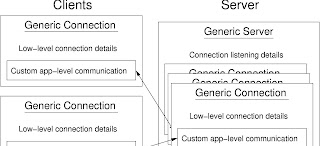
A major challenge in writing the communication API was making it generic enough to be used for any of RFS’s communications needs, while keeping it simple enough so that it doesn’t burden feature development. The solution,illustrated in Figure 2.5, takes advantage of Java’s inheritance paradigm. A generic connection class implements all the lower level details of establishing a connection, and a generic server class implements the details of listening for a connection. Only details specific to a particular communication need to be written on a case-by-case basis.
2.5.1 Crypto Plugin
Because the lower level details of communications are abstracted away from the code that communicates from one component to another, it is possible to add data integrity, privacy, and authentication at the lower level such that the
particular choice of cryptography technology does not impact the functioning of the RFS. In effect, we can plug in a crypto solution; hence, this feature is named the Crypto Plugin.
The Crypto Plugin is implemented as a Java interface. A class which implements the Crypto Plugin interface is dynamically loaded at runtime, and provides the cryptographic services needed to secure communications. The interface relies on Java sockets, so any cryptographic technologies that can be built on top of Java sockets can be implemented as a Crypto Plugin.
RFS comes with two pre-built Crypto Plugins: Plaintext and SSL. The Plaintext plugin is for testing and troubleshooting; it leaves all communications in the clear and provides no data integrity or authentication. The SSL plugin is intended for use in production environments, providing data integrity, secrecy, and authentication.
The RFS SSL Plugin is implemented using the Java SSLSocket and SSLServerSocket classes, which are part of the Java Secure Socket Extension [21]. Each RFS component using the plugin (Agents, Triggers, and Core) has a keystore that contains its public/private key pair, and a truststore that contains certificates for any other components with which it will need to communicate. The component will either create an SSLSocket or an SSLServerSocket, depending on its role in the communication.
The cipher suite used by the RFS SSL Plugin consists of a single entry:
TLS_DHE_RSA_WITH_AES_128_CBC_SHA
This is in contrast to a more typical use of SSL (for example, for Web Browser to Web Server communications) where the cipher suite needs to support many parameters so that a wide variety of clients and servers can be supported. In the
RFS, all the clients and servers using the SSL Plugin can be forced to use the same parameters. Thus, only allowing this set of parameters prevents “dumbing down” attacks [11]. In particular, the RFS SSL Plugin uses Transport Layer
Security (SSL version 3.1) with Diffie-Hellman key exchange using RSA certificates, encryption using the Advanced Encryption Standard (AES) in Cipher Block Chaining mode using 128-bit keys, and SHA-1 for constructing HMACs.Additionally, both client and server authentication are used.
Chapter 3 : Limitations :
~~~~~~~~~~~~~~~~~~~~~~~~~
Though we have created a thorough, robust program to be used for the automatic gathering of forensic data, there are still limitations in our approach.
3.1 Agent Connections
One of RFS’s limitations is directly tied to a feature: the ability to accept analysis results from stand-alone Agents on machines not registered with RFS. This feature is necessary to enable ad hoc analysis of machines. The information is
sent directly into quarantine, but it still requires an open connection and disk space. Thus, an attacker could open an arbitrary number of connections and send an unlimited amount of data to the RFS server. Two DoS attacks are possible: exhausting available connections so real analysis results cannot be received, and exhausting available disk space so real results cannot be stored.
The problem is a complex one since a certain balance is required. The goal of accepting incoming analyses from unknown Agents is important to the mainstream adoption of RFS. Unfortunately, at the same time the RFS needs to be
able to defend against malicious users who attempt to overload the RFS. One possible solution to this problem would be to require the person initiating the stand-alone Agent analysis to enter a password that must be confirmed by the RFS server.
3.2 Slow Information Flow
Another possible DoS attack is slowing the flow of information. When analysis of an Agent is in progress, the Core’s rate limiter will prevent any new analysis of the Agent from starting. Thus, if an attacker can slow or even stop the
collection of information on the Agent, it can effectively prevent any further analysis of that machine. This could be achieved by attaching a debugger to a test executable as it runs, and interrupting its execution.
A possible solution would be to set a timeout value so that the RFS server is prevented from maintaining connections for too long of a time. In order to calculate the timeout value, a weighted average could be recorded for each test, and
the current run time would be compared to that value. If the current run time is larger than some specified number of standard deviations from the weighted average, the collection of data from the Agent would be terminated.
3.3 JRE and Memory
One argument against the RFS is the use of Java as the programming language. Java requires a Java Runtime Environment (JRE) in order to interpret the compiled byte-code. Not only must the byte-code be loaded into memory,but the JRE must also be loaded. This will swap some process information out to disk, thus altering the state of the Agent machine. Causing the memory state of the Agent machine to be changed in this manner does not comply with incident response best practices. Section 3.4 suggests a possible solution.
3.4 Unverified JRE
Another limitation of the current implementation is that the Java Runtime Environment (JRE) is not verified. It could be possible for an attacker to alter the JRE in some way to affect the way in which the RFS does its job. Currently, the
JRE is assumed to be intact. A possible mitigation to this limitation would be to take a secure hash of the entire JRE directory and record the results. When an RFS component is launched, it would compare the current hash of the JRE against the stored version.
This mitigation is incomplete, however, because the JRE itself is involved in verifying its own validity, and if it is cleverly corrupted it could detect when it is checking its own secure hash. A more thorough solution would be to eliminate the JRE altogether by migrating to a different code base or using a Java byte-code to native code compiler so that the RFS components could run without a JRE.
3.5 Kernel Rootkits
Kernel rootkits [24] on Agent machines could go undetected by the RFS. A corrupted kernel can present a false view of system state to user-level programs such as RFS. Thus, rootkits can control what data the kernel returns in response to a
test being run. If the rootkit knows what a “normal” result consists of, then it can essentially hide itself by outputting the “normal” result of tests that might otherwise indicate the rootkit’s presence.
3.6 Test Output Control
In some instances, the attacker may be able to control the output of some tests. For example, the lines of syslog can be controlled by the attacker. If the attacker were to place lines in syslog that matched the test header that the Core uses to differentiate between different tests of an analysis, then the Core would prematurely assume that the Agent is done with its data. This could cause the Core to terminate its connection with the Agent, and lose information that
should have been gathered from the Agent machine.
A solution to this problem would be to have the agent send the size of each test before sending the actual test data. This way delimiters to distinguish between different test results would not be needed, and thus could not be “spoofed” by an
attacker.
3.7 Agent Approach
The Agent approach that we have taken in designing the RFS has its disadvantages. If the Agent software will be installed on many machines, a large initial setup overhead may be incurred. Additionally, if the Agent software needs
to be updated over time, the overhead of updating the software may be just as time consuming as the original install.We have implemented the Agent to allow for remote, on-demand, response kit updating, but updating the Agent software itself has not been automated. The Agent-based approach has scalability issues in terms of installation and maintenance man hours.
3.8 Timing Attacks
There are opportunities for timing attacks against the RFS. If an attacker knows of the existence of the RFS within a network, he can initiate a “red herring” attack to get the RFS to start an analysis on an Agent machine. Once the forensic tests that might reveal a real attack are finished, the real attack commences. The rate-limiting feature in the Core would prohibit a concurrent analysis on the Agent machine, so the next analysis requested by the Trigger would be rejected, and the attack would go unanalyzed and perhaps unnoticed.
A randomization of tests within the response kit may defend against this timing attack. However, the order of certain forensic tests is important, so the randomization technique has limitations. Another possible defense is to run the test
that the attacker may attempt to avoid more than once. For example, one of the tests that an attacker might try to avoid is the list of users logged onto the system. This is a fairly quick test on all systems, so adding additional runs of this test
would not significantly affect the analysis time. Test repetition techniques may defeat such timing attacks; however, this repetition approach has limitations, because it is not feasible to repeat tests that take a long time to complete.
An attacker could simply wait for a long test, such as the file system test, to begin the attack. While this test is being performed, the attacker can launch the attack and erase his tracks before the file system test finishes. A possible defense
against this would be to run tests concurrently. This could detect the attacker’s activities during longer running tests.
3.9 Pass Phrase Problems
As described in Section , RFS uses a pass phrase to establish that the human who launched the RFS Agent had the authority to do so. We assume that someone with this authority will be diligent in verifying that the response kit config
is correct. There are a number of factors prone to failure with this approach. Pass phrases are susceptible to a number of problems [9]. The human operator who launches the RFS Agent may not always be diligent verifying the config. Plus the Agent software itself could have been corrupted.
3.10 Identity Theft
The machine ID scheme presented in Section is not flawless. An attacker can change all three identifying pieces of information on a given machine — the MAC address through a software override, the machine name through the OS configuration, and the machine’s IP address either through the OS configuration or releasing and renewing DHCP leases. If an attacker gains control of two machines on a network that does not use DHCP, it is fairly easy for the attacker to swap the two machines’ identifying information (IP addresses, MAC addresses, and machine names).
Because the Core only uses the IP address, MAC address, and machine name to resolve the machine ID, it cannot detect any changes in the identifying information for machines that have their identities swapped, or for machines for which all three identifiers have changed.
The solution is that the Core must use additional information to resolve the machine ID. The Core could perform some heuristic analysis (sanity checking) of the reported forensics of any machine. The heuristic analysis would entail examining the directory structure, and other information that is classified as non-dynamic, to determine if a machine could realistically be the machine its identifiers claim it is. However, the heuristic analysis may not always succeed in identifying the machine ID. In this case, the analysis results should be stored in the quarantine directory for further analysis by a human to decipher the machine ID.
Chapter 4 : Future Work :
~~~~~~~~~~~~~~~~~~~~~~~~~
There are plenty of directions for future work with the RFS. These additional features would increase the usability, functionality, and security of the RFS.
4.1 Trusted Hardware
We had originally wanted to support trusted hardware on the Agent machines to attest the validity of the Agent’s response kit. It is a difficult problem for the Core to trust the binaries that the Agent will execute, but we believe the current design loosely achieves this property. Trusted hardware would be a more fool-proof approach, but due to time constraints, we were unable to explore this solution.
4.2 Hash Functions
The current version of the RFS uses MD5 as its secure hashing function. While there is no immediate problem with using MD5, users might want the option to use different hash functions. Other secure hash functions, such as SHA-1 and SHA-256, could be added to the implementation. To provide the most robust hash security, a combination of secure hashes could be used.
4.3 Expand the Trigger Mechanism
Currently, the Trigger relies on SWATCH, a third party log watching utility, to send an analysis request to the Core by executing the Trigger program. A future improvement would be to expand the Trigger mechanism to run continuously
and monitor the log data itself, rather than relying on SWATCH. The reduction of reliance on third party software could increase the robustness of the RFS.
4.4 Retro-signatures
By examining analysis results from Agents known to be involved in a particular attack it may be possible to determine a retro-signature for the attack. For example, if a particular set of files is always altered, certain log entries are made, and/or specific ports are open, this data can contribute to creating a retro-signature for the attack. The retro-signatures could be used to detect if the attack had been executed in the past. The retro-signature could be applied to the historical baselines to determine which machines also displayed these characteristics at any given time.
4.5 OS Support
Currently, the response kits support three different operating systems: Windows XP SP2, Windows 2000, and Linux.The infrastructure is in place to easily increase future OS support. It would be beneficial to add support for additional
platforms and platform versions.
Chapter 5 : Related Work :
~~~~~~~~~~~~~~~~~~~~~~~~~~~~
We will now present two existing commercial products and three open-source tools that provide functionality similar to the RFS. The related work section is concluded with a discussion on research in prevention and detection of kernel rootkits.
5.1 Existing Commercial Products
There are two commercial solutions that are relevant to RFS. The most relevant is EnCase Enterprise Edition (EEE),developed by Guidance Software [8]. EEE has a similar system design to RFS (shown in the architecture diagram in Figure 2.1). EEE has Servlets (similar to Agents) that report the results of forensic tests back to the Examiner. The functionality in the RFS Core is split in EEE between the Enterprise Examiner workstation and the SAFE Server. The Enterprise Examiner workstation is where the forensic examiner actually performs analysis of forensic results. The SAFE server is used to perform authentication of users as well as manage user access rights to communicate with Servlets, and brokers the connections so that transactions can be logged.
EEE also integrates with Intrusion Detection Systems (similar to Triggers) to automatically initiate forensic analysis of machines involved in incidents; however, the EEE integration lacks the fine-grained priority control that RFS offers.
EEE has a Snapshot product (similar to the RFS response kit) that captures volatile data from live systems. However,the RFS response kit captures more volatile data, and is extensible so that more volatile data tests can be added as needed.
The EEE Snapshot product has a powerful anomaly detection engine that attempts to detect anomalies in the captured volatile data based on an analysis of historical baseline data. Snapshot not only can capture volatile data, but has the
ability to forensically duplicate drive data and send a bit-stream image of the data to the EnCase Examiner machine.RFS does not provide this feature.
In comparison to the current version of RFS, EEE supports more operating system versions; however, adding support for additional operating systems in RFS is fairly simple. EEE has many other features that RFS does not provide such as search capabilities and reporting features. These features can be future work directions for RFS. Of course, EEE is closed-source, so its correctness cannot be validated, and it comes with a hefty price tag.
The second existing commercial solution is the Paraben forensic tool suite [13]. The suite contains various independent modules for analyzing forensic data, which consumers can choose from to customize the product to fit their needs.
The Forensic Sorter makes a forensic copy of a drive and sorts all files found (even deleted ones) into various categories such as applications, video, audio, compressed files, graphics, documents, text, web, and misc. This allows the examiner to look at the drive image with respect to file type. Forensic Sorter also has a feature to filter out hashes of common files such as innocuous operating system files. Paraben claims that this can reduce the data the examiner must analyze by 20%–30%.
Paraben’s Case Agent Companion uses the sorted data from Forensic Sorter to provide a case management system where the examiner can examine the captured data, make notes on any findings, bookmark references to data, log the analysis progress, search within files, and generate a report of findings.
Paraben’s other software modules include tools for seizing cell phone data, capturing PDA data, analyzing chat data,examining email data, decrypting data, and more. All of these modules are compatible with each other so the customer
can purchase a tailored solution. This product only automates the data collection, data analysis, and reporting parts of the incident response process. Paraben’s software must be manually initiated and does not interface with IDSes. The
software does not currently support remote acquisition of data, so the examiner must physically visit the victim machine to analyze it.
5.2 Existing Open-Source Products
There are several open-source products that have similar functionality or a subset of the functionality of the Remote Forensics System. These products are either simple data acquisition tools or more robust systems, similar to the RFS.
5.2.1 The Coroner’s Toolkit
The Coroner’s Toolkit (TCT) [5] is a freely available collection of tools that can be used for a post-mortem analysis of a UNIX system after an attack. The toolkit includes many tools similar to the RFS response kit tools; however, TCT
contains tools beyond what the RFS provides such as a deleted file recovery tool. The authors are explicit in mentioning that TCT is only for post-mortem collection.
5.2.2 FirstOnScene
FirstOnScene [12] is a another freely available data acquisition tool. FirstOnScene is a Visual Basic script that gathers forensic data from a system using about 20 different freely available tools. It is designed to be run on Windows systems
(W2K, WXP, and W2K3). The current version must be run from a trusted source, such as a CD. The author plans to be add the ability to initiate FirstOnScene remotely, and a base lining feature, both of which the RFS provides.
5.2.3 Forensic Server Project
The Forensic Server Project (FSP) [2] is proof-of-concept tool developed by Harlan Carvey. The use of the FSP is similar to the RFS. There is a server-client relationship setup in order to collect data from the clients and transfer the
results of a series of forensic tests to the server. While the FSP is only intended for Windows environments, it is written in Perl and, with minor adjustments, should be able to work in other environments as well.
The client portion is referred to as the First Responder Utility (FRU), which is analogous to the RFS stand-alone Agent.It is intended to be burned to a CD and run from the CD drive of the potentially compromised system. Users can easily
customize their own set of tests to be run on the victim machine and send the results to the server. The server portion is referred to as the FSP. It handles all of the case management and storage of data from the victim machines. The FSP listens on a port for connections from an FRU, and stores the data that is received. Hashes of the data are stored along with a log of the tests run by the FRU.
There are some key differences between the RFS and FSP. The functionality of the FSP is a subset of the functionality of the RFS. When the RFS is used with a stand-alone Agent and a Core-lite, the RFS acts very much like the FSP. However, when run in full mode, the RFS provides features above and beyond what the FSP can provide.
5.3 Trusting the Operating System
In Section 3.5 we describe how attackers can hide their presence from response kit binaries. We will now describe related efforts to detect when rootkits are installed as well as prevention techniques. Incorporating these techniques into RFS could solve its current weakness collecting forensic data from machines with compromised kernels.
Early work in this field was done by Dino Dai Zovi and is detailed in his paper, Kernel Rootkits [24]. Rootkits that use LKMs (loadable kernel modules) as their entry point can be detected, and it is also possible to prevent their installation.
LKM rootkits frequently redirect system calls to call wrappers that hide their malicious activity. These changes can be detected by comparing system call memory addresses in System.map with the system call table addresses of the running kernel.
Zovi presents three strategies for preventing LKM installation. First, LKMs can be disabled altogether. However, this does not defeat kernel modules that write directly to /dev/kmem. Further, LKMs can be beneficial, because they allow the kernel to be extended without recompilation.
The second prevention strategy is to use Securelevels (introduced in 4.4BSD), which prevents users, even the superuser, from turning off certain file flags, writing to kernel memory via /dev/mem or /dev/kmem, loading kernel modules, and altering the firewall configuration. According to UNIXguide.net [22], the limitation of this feature is that the “securelevel” is set late in the boot process, which gives an attacker a window in which to execute their code before the “securelevel” is elevated. Additionally, all files in the boot process must be trusted, which is not always easy.
The third prevention strategy is to only use cryptographically signed kernel modules. This solution could work if signed kernel modules were widely supported; unfortunately, they currently are not.
More recently, Garfinkel, et. al. developed Livewire, a virtual machine monitor to isolate an intrusion detection system from the host it is monitoring [7]. This could allow the monitor to detect the presence of malicious rootkits because it
monitors the discrepancies between what the operating system reports (through various user-level programs such as ps and netstat) and the state of the hardware and kernel. The Virtual Machine Introspection (VMI) IDS can also detect
when an attacker modifies an in-memory process by inspecting the immutable pages of the process. This may detect attacks where the user uses ptrace to modify the memory image of a process.
In Livewire, the user defines a policy module which defines when the VMI IDS checks for intrusion. Sample policies include polling at a given frequency and event-driven inspections. If the attacker is aware of this policy, the attacker may be able to remove their tracks when the inspection takes place. Livewire can be a valuable addition to Agent machines to help ensure that the OS has not been subverted to report incorrect results to the response kit.
Petroni, et. al. [14] have developed Copilot, a kernel runtime integrity monitor that runs on a PCI card connected to the host machine. Copilot is robust to compromise of the host OS because it directly accesses the host’s memory via DMA
to detect kernel compromises and uses an independent communication channel with an admin station that is not dependent on the host’s network stack. The Copilot co-processor monitors the hash of memory containing kernel or LKM code as well as the hash of memory containing tables of jump addresses for kernel function pointers. These are two memory regions that are frequently altered by rootkits. One limitation of this work is that it will not detect attacks that modify memory regions that are not monitored. Regardless, the Copilot approach would also be a beneficial
augmentation to Linux-based Agents to detect the installation of rootkits.
Chapter 6 : Conclusions :
~~~~~~~~~~~~~~~~~~~~~~~~~~~
6.1 Goals
We have developed a tool that automates the forensic data acquisition process. The Remote Forensic System provides a service that we believe will be useful to security professionals who manage a large networking environment. We have achieved the following goals:
Goals Reached
1 Automate incident response process
2 Collect data in a forensically sound manner
3 Perform manual and automatic analysis
4 Transmit results securely
5 Minimize trusted computing base (TCB)
6 Provide for extensibility
7 Facilitate results analysis
6.1.1 Automate incident response process
RFS automates a large portion of the incident response process, illustrated in Figure 1.2. The Agent automates the “data collection” phase. The Core automates the “pre-incident response” phase by scheduling baselines, the “formulate
response strategy” phase by considering priority and impact thresholds, and the “analysis” and “reporting” phases via the web interface. The Trigger automates “initial response” and “formulate response strategy” by passing incident data, priority, and impact to the Core.
6.1.2 Collect data in a forensically sound manner
We followed the best practices of forensic data acquisition. The RFS gathers regular baselines of registered Agent machines for analysis and comparison. The date and time of the Agent and the Core are recorded for the beginning and end all analyses. Trusted tools are used for performing the tests on the Agent machines. Before execution, the hashes of these tools are checked against their known, good hashes in order to ensure that the tool is still the trusted version. At the end of an analysis a hash is taken of the entire result set and securely stored in order to check the integrity of the results at a later date.
6.1.3 Perform manual and automatic analysis
The analyses can be either manually or automatically initiated. A manual analysis can be initiated from either a stand-alone Agent to be delivered to the Core or manually initiated using the Core’s GUI. An automatic analysis can be
initiated by a Trigger in response to an event from a device such as an IDS. Automatic analyses can also be initiated by the Core’s periodic triggering mechanism.
6.1.4 Transmit results securely
The data collection process has been designed to be performed in a secure manner. With the Crypto Plugin, users can customize the level of security and the algorithms they need. With the Crypto Plugin infrastructure, RFS can authenticate Agent machines to ensure that they are who they claim to be. Likewise, data transmission can be encrypted during transfer to provide data secrecy.
6.1.5 Minimize trusted computing base (TCB)
The Trusted Computing Base (TCB) was minimized as much as possible for the amount of time we had. The majority of the TCB lies within the Core. The Core is trusted to securely store the results of analyses. If the Core is compromised, we can no longer trust any of the forensic results. At this point the system is useless. The Triggers and Agents only minimally affect the TCB. If an attacker is able to learn the Trigger’s private key, the attacker can authenticate to the Core and send false triggers. This may simply make the Core less efficient. If an Agent is
compromised, the Agent may be able to submit false analysis results; however, as long as the attacker is unable to DoS the Core, the overall RFS infrastructure is unaffected, and the Core can continue to do its job. If an Agent is compromised, its forensic results that were stored at the Core before the compromise can still be trusted.
6.1.6 Provide for extensibility
The RFS is extensible. Users may customize Crypto Plugins in order to fit their security needs. Developers of new Java Crypto Plugins only need to worry about implementing the CryptoPlugin interface. New forensic tests can be added to the response kit by editing the rkconfig.xml file. The Trigger is also extensible to new event-generating devices as long as the device allows customized event responses.
6.1.7 Facilitate results analysis
The web interface streamlines the examination of forensic analysis results from a large number of sources at many different points in time. The ability to compare new analyses to older analyses provides a method to identify possible breaches in security and their corresponding attack signatures.
6.2 Tool to be used by IT Professionals
The RFS is a multi-faceted tool for use by IT professionals. Automatic machine data gathering is performed for regular baselines and in response to network or host events.
The RFS offers many ways to store the results of forensic analyses. IT professionals analyzing a machine not registered to the RFS have various options of where to store the results. They can send the results to the RFS Core where it will be placed into quarantine, they can pipe the output to netcat, or they can store the results to a local file or device such as a USB key.
We have created a forensics system to automate a large portion of the incident response process. Great attention has been given to performing these tasks in a secure and authenticated manner. The RFS has limitations and areas for future
work, but the benefits of the RFS are significant. No existing forensics tool offers the feature set and security properties provided by the RFS.
Appendix A
Installation:
RFS is distributed as a zip archive for Windows and as a gzipped tar archive for Linux. Basic installation is simply a matter of decompressing the archive in the directory where you would like it to run. For example, in Linux use the following command:
> tar zxvf rfs-linux-20050427-0026.tar.gz
This will install all of the RFS components (Agent, Core, and Trigger), as well as the Sun JRE. Note that the naming convention for RFS archive files is:
rfs-
--.
Examples:
rfs-winxp-20050427-0026.zip
rfs-win2k-20050427-0026.zip
rfs-linux-20050427-0026.tar.gz
After this basic installation, a few additional steps should be taken. Generally, any individual computer will only be used as a single RFS component, and files only needed by the other components should be removed. The full version of the web interface requires additional steps, as well. Finally, once RFS is up and running in a test environment, SSL should be enabled before installing in a production environment. All of these installation steps are covered below.
A.1 Agent
The following files can be removed from Agent installations:
Core_GUI_help.html
core.jar
rfs.css
serverconfig.xml
trigger.jar
The following directories can be removed from Agent installations:
Core_GUI_help_files
Images
www
A.2 Core
The following files can be removed from Core installations:
agent-sa.jar
agent.jar
trigger.jar
The following directories can be removed from Agent installations:
Core_GUI_help_files
Images
www
A.2 Core
The following files can be removed from Core installations:
agent-sa.jar
agent.jar
trigger.jar
A.4 Web Interface
The RFS Core has a built-in, single-purpose web server that provides the basic RFS Web Interface. Thus, installing the Core also installs the Web Interface, and as long as the Core is running the Web Interface will be available. By default
the Web Interface runs on port 80. To change the port, edit the following setting in serverconfig.xml:
80
In addition to the basic Web Interface, a frame-based Web Interface with context-sensitive help is also available. To install this “full” version of the web interface, a general-purpose web server such as Apache or Microsoft IIS is
required. The web interface files are located in the www directory. Create a virtual directory for this directory in your web server’s configuration. Make sure that your web server is running on a different port from the basic RFS web interface so they do not conflict.
Next, add a reference to the basic RFS web interface in the file frame.html:
Change rhenium-ini.ini.cmu.edu:8000 to your server’s name and the port number of the basic web interface:
Finally, add a reference to your general-purpose web server in serverconfig.xml. Change rhenium-ini.ini.cmu.edu:8888 to your server’s name and the port number of general-purpose web server:
http://rhenium-ini.ini.cmu.edu:8888/
Note that the general-purpose web server does not necessarily need to run on the same computer as the RFS Core. In this case, simply make sure the reference in frame.html is to the computer running the RFS Core, and the reference
in serverconfig.xml is to the computer running the general-purpose web server.
Once the web interface has been installed, see Section B.4 for usage instructions.
A.5 SSL
The RFS SSL Plugin provides data integrity, secrecy, and authentication. This section explains the steps necessary to enable the SSL Plugin. On each computer with an RFS component:
• Create a self-signed public/private key pair, stored in a keystore
• Export a certificate for use by other RFS components
• Import certificates for all RFS components that will communicate with this component, stored in a truststore.
• Configure this component to use the SSL plugin.
You will need to use keytool [19], a utility available from Sun Microsystems, Inc., to create the keystore and truststore. Each of these steps is described in detail below
A.5.1 Create public/private key pair
The first step is to create a public/private key pair, along with a self-signed RSA certificate for the public key, and store this in a keystore:
> keytool -genkey -keyalg RSA -alias -keystore keystore.jks
Where is a unique alias that will be used to identify the certificate. Using the computer’s name may help avoid confusion later on.
You will be prompted for a keystore password. Choose this password carefully — it will be requested every time you start the RFS component (Note: keytool does not hide the password when you type it, so be sure no one can observe you during this process). Next you will be prompted for information to be stored in the certificate. Finally you will be asked for a password for the certificate. Press RETURN to use the same password that you chose for the keystore.
A.5.2 Export certificate
Now you will export the public key certificate so it can be used to establish SSL sessions with other RFS components:
> keytool -export -alias -file .cer -keystore keystore.jks
where is the same alias you chose in the previous step. You will be prompted for the keystore password, then the certificate will be exported into the file .cer.
A.5.3 Import certificates
The next step is to import certificates for all components that will need to communicate with this component. Agents and Triggers only need to import the Core’s certificate, while the Core needs to import certificates for all Agents and
Triggers:
> keytool -import -alias -file .cer -keystore truststore.jks
where is the alias of the certificate to be imported. You will be prompted for a password for the truststore. keytool does not distinguish between keystores and truststores, and its prompt will request a keystore password. Just
realize that this password does not need to be the same as the keystore password you entered previously, although it can be if you prefer. You will be prompted to verify that you trust this certificate. Enter “yes”, and the certificate will be
imported. Repeat this step for all certificates that need to be imported, using the same password you did for the first import.
A.5.4 Configure component
Finally, we need to configure the RFS component to actually use the SSL Plugin. This step is different for each component type.
Agent
You specify which Crypto Plugin the Agent uses on the command line when you launch it. To use the SSL Plugin, launch Agent with the option –crypto SSLPlugin. For example:
> agent -p 3333 --crypto SSLPlugin
Core
In the Core the Crypto Plugin is specified in serverconfig.xml. Change the following entry from PlaintextPlugin to SSLPlugin:
PlaintextPlugin
Trigger
The Trigger specifies the Crypto Plugin on the command line just like the Agent. For example:
> trigger -i 192.168.30.13 -p 5555 --crypto SSLPlugin [...]
Appendix B
Usage
RFS, as a whole, is a large and complicated tool, but its use is relatively straightforward when approached one component at a time. The first step is to use the Agent as a stand-alone incident response kit. Next, use the Core to
collect results. After this, set up a Trigger to initiate analyses in response to incidents. Finally, use the Web Interface to examine the results of the analyses. The usage of each of these components is covered in this section.
B.1 Agent
The RFS Agent can be used as a stand-alone response kit or as a component of the full RFS architecture. This section covers how to launch the Agent in either mode and how to make changes to the Agent’s response kit.
B.1.1 Response Kit Editing
The Agent’s response kit is defined in an XML config file called rkconfig.xml. The test executables are stored in the bin/ directory, where is wxp, w2k, or lnx. The config file can be edited by hand, or the stand-alone Agent can be used. If you are adding new test executables, copy these to the appropriate directory before editing the response kit config.
> agent-sa --config
Follow the on-screen instructions to edit the response kit.
B.1.2 Stand-alone Agent
The Agent can be used in stand-alone mode to run ad hoc analyses:
> agent-sa [OPTIONS]
The following is the set of options available:
-h,--help Display help text
-o,--output File where results will be stored.
If this option is present, --ipaddr, --port, and --crypto will be ignored.
-i,--ipaddr IP address of the core
-p,--port Port on which the core is listening [1025-65535]
-c,--crypto Crypto-plugin class to use for communication
-f,--full Perform a full analysis. Light analysis is default.
--config Configure the response kit
--platform With --config, specifies which platform to configure ("XP", "Linux", "W2K").
If absent, the current platform is chosen by default.
--file Specifies a file from which response kit configuration settings are loaded
-a,--interactive Run the agent in interactive mode.
-d,--describe Print descriptions of forensic tests.
The interactive option will step you through the process of running a forensic analysis, and is a good way to get familiar with the RFS Agent’s features.
B.1.3 Automated Agent
To fully utilize RFS, the Agent should be used in automated mode:
> agent [OPTIONS]
The following is the set of options available:
-h,--help Display help text
-p,--port Port on which agent listens [1025-65535]
-c,--crypto Crypto-plugin class to use for communication
B.2 Core
The Core has two modes: normal and “lite.” “Lite” mode is enabled by including the -l flag, while normal mode is default. In normal mode, the Core has greater functionality and includes features such as analysis scheduling, CVS
storage of results, rate limiting of forensic analyses, GUI interaction, and interaction with triggering mechanisms.Running the Core in “lite” mode will run the core without any of the above features. The “lite” core simply listens on a
given port for forensic analysis submissions from “stand-alone” agents.
B.2.1 Core Lite
To run the Core in “lite” mode:
> core -l
B.2.2 Core
To run the Core in normal mode:
> core [OPTIONS]
The following is the set of options available:
-h,--help Display this help text
-n,--nogui Do not show the GUI when running. This option does not allow you to configure the server while it is running.
-l,--lite
Specify the port for receiving analyses and disable all core functionality except receiving analyses.
The usage of the core GUI is described in the Core_GUI_help.html file that is packaged with the software.
B.3 Trigger
The trigger setup is very basic and requires a minimal amount of configuration. A basic installation of Snort and SWATCH are the third party tools required to take full advantage of the Trigger.
B.3.1 Configuration
The configuration of the Trigger has two portions, the Trigger software running on the Trigger machine that parses alert information and the impact analysis performed on the RFS server.
The Trigger software is configured entirely with command line options. The Trigger is initiated as follows:
> trigger [OPTIONS]
The following set of options are available:
-h,--help Display this help text
-i,--ipaddr IP address of the core
-p,--port Port on which the RFS server listens [1025-65535]
-c,--crypto Crypto-plugin class to use for communication
-s,--sourceIP IP address of the source of an alert
-t,--targetIP IP address of the target of an alert
-P,--priority Priority of the alert
-I,--info Extra information about an alert that may be of use to the core
The -i, -p, and -c options are required, while the others are optional. At least one of -s, -t, or -I should be used so that there is some useful information sent to the Core. If none of these options are used, then a trigger cannot be generated, since there is no information on which to base an analysis.
Example SWATCH Configuration
SWATCH version 3.1.1 [1] was used in our test environment. SWATCH can be configured to monitor syslog for Snort alerts. Information that is parsed from the Snort alert includes the priority level, the source IP address, and the target IP address.
Below is a sample SWATCH configuration file that was used for our tests:
watchfor /^.*snort.*\[Priority: (.)\].* (\d+\.\d+\.\d+\.\d+).* ->
(\d+\.\d+\.\d+\.\d+).*$/
exec /path/to/trigger -i 192.168.2.2 -p 5555 -c SSLPlugin -s $2 -t $3 -P $1
-I \"$&\"
watchfor /^.*snort.* (\d+\.\d+\.\d+\.\d+).* -> (\d+\.\d+\.\d+\.\d+)(.*)$/
exec /path/to/trigger -i 192.168.2.2 -p 5555 -c SSLPlugin -s $1 -t $2 -P 4 -
I \"$&\"
The first rule watches for alerts that contain a priority number. Some Snort alerts do not contain a priority number, such as those caught by a Snort preprocessor. Alerts without priority numbers are matched by the second rule. In the second
rule, the priority level of 4 is always provided to the trigger. Each rule consists of a Perl regular expression designed to match the Snort alerts. The lines that begin with “exec” execute the Trigger with the proper Core IP address, port,
crypto plugin, the information parsed from the alert.
Snort Configuration
Snort version 2.3.2 [15] was used in our tests. Snort requires minimal configuration in order to be used with the Trigger. Snort simply needs to be configured properly to log to the syslog facility in Linux. The following line in the default Snort configuration achieves this:
output alert_syslog: LOG_AUTH LOG_ALERT
The user may want to only invoke the Trigger in response to certain alerts. This can be achieved in two different ways.The first way is for Snort to be configured to only log certain events to syslog. The second way is to add more complexity to the SWATCH regular expressions so that SWATCH only reacts to certain Snort alerts.
Another customization that can be done on the Trigger machine side is the priority of different types of alerts. In order to have the priority levels correspond to the priority scheme that the RFS uses, the priorities need to be changed. Snort
has a lower number represent a higher priority, meaning that 1 is the highest priority level, and a higher number is a lower priority level. The RFS is just the opposite, with 5 being the highest priority, and 1 being the lowest. In order to
change Snort’s default priority levels, the user needs to edit the classification.config file that is a part of the Snort configuration. The following line is an example of a Snort priority customization.
config classification: bad-unknown, Potentially Bad Traffic, 2
The configuration line begins with the initialization code followed by a colon. The “bad-unknown” identifier is pre-defined brief description of the alert type. The “Potentially Bad Traffic” is a name for the classification. The number 2
at the end of the line is the priority number that Snort will give alerts that match the “bad-unknown” criteria. The user can customize the priorities assigned to alerts by changing the priority values at the end of these lines.
The impact analysis (see Section 2.4.4) criteria can be configured at the RFS server. The criteria for medium and large impact levels can be configured in the serverconfig.xml file. The large impact criteria configuration is a straight-
forward keyword list. Any keywords that should trigger an analysis of the entire network should be placed in this list. Below is an example configuration for the large impact criteria in the serverconfig.xml file.
EXPLOIT
BACKDOOR
This configuration states that any Snort alerts containing the keywords “EXPLOIT” or “BACKDOOR” (case sensitive)will trigger analyses of all machines.
The serverconfig.xml file also contains a list of medium impact alert groups. If one IP address in a mediumimpact alert group is directly involved in an alert, all other IP addresses in that group will be analyzed as well. Below is an example from the serverconfig.xml file:
192.168.2.3
192.168.2.4-10
---
192.168.2.2
192.168.2.5
192.168.2.27
This example configuration creates two medium impact alert groups delimited by the three-dash entry. If the IP address 192.168.2.3 is directly involved in an alert (it is either the source or target machine), then an analysis will also be
initiated for all machines within the range of 192.168.2.4 to 192.168.2.10. Likewise, if there is an alert for machine 192.168.2.2, then the machines 192.168.2.5 and 192.168.2.27 will also be analyzed.
B.4 Web Interface
Sifting through the massive amounts of data generated during a forensic analysis is a daunting task. The RFS Web Interface facilitates investigation of analysis results collected by the RFS. Results are organized by machine, and the entire history of results is available. Line-by-line comparisons of test results ease the task of determining what the consequences of a particular incident were.
If the Web Interface has not yet been installed, see Section A.4. There are two versions of the Web Interface — a basic version that is part of the RFS Core, and a full version that runs on a general-purpose web server. The full version is optional, and adds extra installation steps. However, it is recommended for new users because it provides context-sensitive help.
Let us assume your server is named rfs.myserver.com, that the basic Web Interface is running on port 8000, and the full web interface is running on port 8888.
Open a web browser and navigate to http://rfs.myserver.com:8888 to access the full web interface. You will see a splash page with a brief description of RFS. Click the link at the bottom of the page to enter the interface. You will see three panes. The large pane on the right is the basic web interface.
Instructions for using all the features of the basic web interface are included in the help system. The pane on the top-left contains the help system, and the pane on the bottom-left contains individual help pages. You can also obtain context-
sensitive help for your current location in the basic interface by clicking the Help link in the upper-right.














